开发准备
- 您已经成功开通浪潮云服务,创建了用户名和密码,并创建了HDInsight实例。
- 您已经对Hadoop、Spark、Hive和大数据产品具备一定的认识。
- 您已经对Java和Scala语法具备一定的认识。
- 您已经对浪潮云大数据-HDInsight服务中的开发组件有一定的了解。
Spark开发指南
开发指引
概述
在一个较高的概念上来说,每一个Spark应用程序由一个在集群上运行着用户的main函数和执行各种并行操作的driver program(驱动程序)组成。Spark提供的主要抽象是一个弹性分布式数据集(RDD),它是可以执行并行操作且跨集群节点的元素的集合。RDD可以从一个 Hadoop文件系统(或者任何其它 Hadoop 支持的文件系统),或者一个在 driver program(驱动程序)中已存在的Scala集合,以及通过 transforming(转换)来创建一个RDD。用户为了让它在整个并行操作中更高效的重用,也许会让 Spark persist(持久化)一个 RDD到内存中。最后,RDD会自动的从节点故障中恢复。
在Spark中的第二个抽象是能够用于并行操作的shared variables(共享变量),默认情况下,当 Spark的一个函数作为一组不同节点上的任务运行时,它将每一个变量的副本应用到每一个任务的函数中去。有时候,一个变量需要在整个任务中,或者在任务和driver program(驱动程序)之间来共享。Spark支持两种类型的共享变量 : broadcast variables(广播变量),它可以用于在所有节点上缓存一个值,和accumulators(累加器),他是一个只能被“added(增加)”的变量,例如counters和sums。
Spark依赖
Spark2.2.0默认使用Scala 2.11来构建和发布直到运行。(当然,Spark 也可以与其它的 Scala 版本一起运行)。为了使用 Scala 编写应用程序,您需要使用可兼容的 Scala 版本(例如2.11.X)。
要编写一个 Spark 的应用程序,您需要在Spark上添加一个Maven依赖。Spark可以通过Maven中央仓库获取:
groupId = org.apache.spark
artifactId = spark-core_2.11
version = 2.2.0
此外,如果您想访问一个HDFS集群,则需要针对您的HDFS版本添加一个hadoop-client(hadoop 客户端)依赖。
groupId = org.apache.hadoop
artifactId = hadoop-client
version = your-hdfs-version
最后,您需要导入一些 Spark classes(类)到您的程序中去。添加下面几行:
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
初始化Spark
程序必须做的第一件事情是创建一个SparkContext对象,它会告诉Spark如何访问集群。要创建一个 SparkContext,首先需要构建一个包含应用程序的信息的SparkConf对象。
每一个JVM可能只能激活一个SparkContext 对象。在创新一个新的对象之前,必须调用 stop() 该方法停止活跃的SparkContext。
val conf = new SparkConf().setAppName(appName).setMaster(master)
new SparkContext(conf)
这个appName参数是一个在集群 UI 上展示应用程序的名称。 master是一个Spark, Mesos或YARN的 cluster URL,或者指定为在local mode(本地模式)中运行的 “local” 字符串。在实际工作中,当在集群上运行时,您不希望在程序中将 master给硬编码,而是用使用spark-submit启动应用并且接收它。然而,对于本地测试和单元测试,您可以通过“local”来运行Spark进程。
使用Shell
在Spark Shell 中,一个特殊的 interpreter-aware(可用的解析器)SparkContext 已经为您创建好了,称之为sc的变量。创建您自己的SparkContext将不起作用。您可以使用--master参数设置这个SparkContext连接到哪一个master上,并且您可以通过--jars参数传递一个逗号分隔的列表来添加 JARs到classpath中。也可以通过 --packages参数应用一个用逗号分隔的maven coordinates(maven 坐标)方式来添加依赖(例如,Spark 包)到您的shell session 中去。任何额外存在且依赖的仓库(例如 Sonatype)可以传递到 --repositories 参数。例如,要明确使用四个核(CPU)来运行 bin/spark-shell,使用:
$ ./bin/spark-shell --master local[4]
$ ./bin/spark-shell --master local[4] --jars code.jar
$ ./bin/spark-shell --master local[4] --packages "org.example:example:0.1"
弹性分布式数据集(RDDs)
概述
主要以一个弹性分布式数据集(RDD)的概念为中心,它是一个容错且可以执行并行操作的元素的集合。有两种方法可以创建RDD : 在你的 driver program(驱动程序)中parallelizing一个已存在的集合,或者在外部存储系统中引用一个数据集,例如,一个共享文件系统,HDFS,HBase,或者提供 Hadoop InputFormat的任何数据源。
RDD操作
RDDs support两种类型的操作: transformations(转换), 它会在一个已存在的dataset上创建一个新的dataset,和actions(动作),将在 dataset上运行的计算后返回到driver 程序。例如,map 是一个通过让每个数据集元素都执行一个函数,并返回的新RDD结果的transformation, reduce reduce通过执行一些函数,聚合RDD中所有元素,并将最终结果给返回驱动程序(虽然也有一个并行 reduceByKey返回一个分布式数据集)的action。
Spark中所有的transformations都是lazy(懒加载的), 因此它不会立刻计算出结果。相反, 他们只记得应用于一些基本数据集的转换 (例如. 文件)。只有当需要返回结果给驱动程序时,transformations才开始计算。 这种设计使Spark的运行更高效, 例如我们可以了解到,map 所创建的数据集将被用在reduce 中,并且只有reduce的计算结果返回给驱动程序,而不是映射一个更大的数据集。
默认情况下,每次你在RDD运行一个action的时,每个transformed RDD都会被重新计算。但是,您也可用persist(或 cache)方法将RDD persist(持久化)到内存中;在这种情况下,Spark为了下次查询时可以更快地访问,会把数据保存在集群上。此外,还支持持续持久化RDDs到磁盘,或复制到多个结点。
基础
为了说明 RDD 基础,请思考下面这个的简单程序:
<pre><code>val lines = sc.textFile("data.txt")
val lineLengths = lines.map(s => s.length)
val totalLength = lineLengths.reduce((a, b) => a + b)
</code></pre>
第一行从外部文件中定义了一个基本的RDD,但这个数据集并未加载到内存中或即将被行动:line仅仅是一个类似指针的东西,指向该文件。 第二行定义了lineLengths作为map transformation的结果。请注意,由于laziness(延迟加载)lineLengths不会被立即计算。最后,我们运行reduce,这是一个 action。此时,Spark分发计算任务到不同的机器上运行,每台机器都运行在map的一部分并本地运行 reduce,仅仅返回它聚合后的结果给驱动程序。
如果我们也希望以后再次使用 lineLengths,我们还可以添加:
<pre><code>lineLengths.persist()
</code></pre>
在reduce 之前,这将导致lineLengths在第一次计算之后就被保存在 memory 中。
传递Functions(函数)给Spark
Python当driver程序在集群上运行时,Spark的API在很大程度上依赖于传递函数。有2种推荐的方式来做到这一点:Anonymous function syntax(匿名函数语法), 它可以用于短的代码片断。在全局单例对象中的静态方法。例如您可以定义object MyFunctions传递MyFunctions.func1,如下:
<pre><code>object MyFunctions {
def func1(s: String): String = { ... }
}
myRdd.map(MyFunctions.func1)
</code></pre>
请注意,虽然也有可能传递一个类的实例(与单例对象相反)的方法的引用,这需要发送整个对象,包括类中其它方法。例如,考虑:
<pre><code>class MyClass {
def func1(s: String): String = { ... }
def doStuff(rdd: RDD[String]): RDD[String] = { rdd.map(func1) }
}
</code></pre>
这里,如果我们创建一个 MyClass 的实例,并调用 doStuff,在 map 内有 MyClass 实例的 func1 方法的引用,所以整个对象需要被发送到集群的。它类似于 rdd.map(x => this.func1(x))类似的方式,访问外部对象的字段将引用整个对象:
<pre><code>class MyClass {
val field = "Hello"
def doStuff(rdd: RDD[String]): RDD[String] = { rdd.map(x => field + x) }
}
</code></pre>
相当于写 rdd.map(x => this.field + x), 它引用 this 所有的东西. 为了避免这个问题, 最简单的方式是复制 field 到一个本地变量,而不是外部访问它:
<pre><code>def doStuff(rdd: RDD[String]): RDD[String] = {
val field_ = this.field
rdd.map(x => field_ + x)
}
</code></pre>
理解闭包
在集群中执行代码时,一个关于Spark更难的事情是理解变量和方法的范围和生命周期。修改其范围之外的变量RDD操作可以混淆的常见原因。在下面的例子中,我们将看一下使用的foreach() 代码递增累加计数器,但类似的问题,也可能会出现其他操作上。
考虑一个简单的RDD元素求和,以下行为可能不同,具体取决于是否在同一个JVM 中执行。一个常见的例子是当Spark运行在local本地模式(--master = local[n])时,与部署Spark应用到集群(例如,通过spark-submit到YARN):
<pre><code>var counter = 0
var rdd = sc.parallelize(data)
// Wrong: Don't do this!!
rdd.foreach(x => counter += x)
println("Counter value: " + counter)
</code></pre>
Local(本地)vs.cluster(集群)模式
上面的代码行为是不确定的,并且可能无法按预期正常工作。执行作业时,Spark会分解RDD操作到每个 executor中的task里。在执行之前,Spark计算任务的closure(闭包)。闭包是指executor要在RDD上进行计算时必须对执行节点可见的那些变量和方法(在这里是foreach())。闭包被序列化并被发送到每个executor。
闭包的变量副本发给每个executor,当counter被foreach函数引用的时候,它已经不再是driver node的counter了。虽然在driver node仍然有一个counter在内存中,但是对executors已经不可见。executor看到的只是序列化的闭包一个副本。所以counter最终的值还是0,因为对counter所有的操作均引用序列化的closure内的值。
在local本地模式,在某些情况下的foreach功能实际上是同一JVM上的驱动程序中执行,并会引用同一个原始的counter计数器,实际上可能更新.
为了确保这些类型的场景明确的行为应该使用的Accumulator累加器。当一个执行的任务分配到集群中的各个worker结点时,Spark的累加器是专门提供安全更新变量的机制。本指南的累加器的部分会更详细地讨论这些。
在一般情况下,closures - constructs像循环或本地定义的方法,不应该被用于改动一些全局状态。Spark 没有规定或保证突变的行为,以从封闭件的外侧引用的对象。一些代码,这可能以本地模式运行,但是这只是偶然和这样的代码如预期在分布式模式下不会表现。如果需要一些全局的聚合功能,应使用Accumulator(累加器)。
RDD Persistence(持久化)
Spark中一个很重要的能力是将数据persisting持久化(或称为caching缓存),在多个操作间都可以访问这些持久化的数据。当持久化一个RDD时,每个节点的其它分区都可以使用RDD在内存中进行计算,在该数据上的其他action操作将直接使用内存中的数据。这样会让以后的action操作计算速度加快(通常运行速度会加速 10 倍)。缓存是迭代算法和快速的交互式使用的重要工具。
RDD可以使用persist()方法或cache()方法进行持久化。数据将会在第一次action操作时进行计算,并缓存在节点的内存中。Spark的缓存具有容错机制,如果一个缓存的RDD的某个分区丢失了,Spark将按照原来的计算过程,自动重新计算并进行缓存。
另外,每个持久化的RDD可以使用不同的storage level存储级别进行缓存,例如,持久化到磁盘、已序列化的Java对象形式持久化到内存(可以节省空间)、跨节点间复制、以 off-heap 的方式存储在 Tachyon。这些存储级别通过传递一个StorageLevel对象(Scala, Java, Python) 给persist()方法进行设置。cache()方法是使用默认存储级别的快捷设置方法,默认的存储级别是 StorageLevel.MEMORY_ONLY(将反序列化的对象存储到内存中)。
Spark Streaming
概述
Spark Streaming是Spark Core API的扩展,它支持弹性的,高吞吐的,容错的实时数据流的处理。数据可以通过多种数据源获取, 例如Kafka,Flume,Kinesis以及TCP sockets,也可以通过例如 map,reduce,oin,window等的高级函数组成的复杂算法处理。最终,处理后的数据可以输出到文件系统, 数据库以及实时仪表盘中。事实上,你还可以在data streams(数据流)上使用机器学习以及图计算算法。

在内部, 它工作原理如下, Spark Streaming接收实时输入数据流并将数据切分成多个batch(批)数据,然后由Spark引擎处理它们以生成最终的stream of results in batches(分批流结果)。
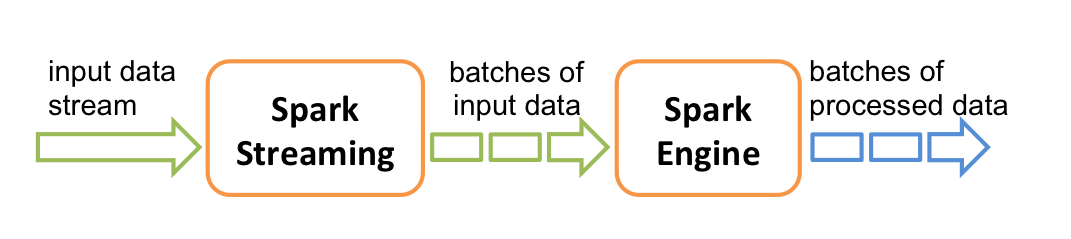
Spark Streaming提供了一个名为discretized stream或DStream的高级抽象, 它代表一个连续的数据流。DStream可以从数据源的输入数据流创建,例如Kafka,Flume以及Kinesis,或者在其他DStream上进行高层次的操作以创建。在内部,一个DStream是通过一系列的RDDs来表示。
本指南告诉你如何使用DStream来编写一个Spark Streaming程序。 你可以使用Scala,Java或者 Python(Spark 1.2 版本后引进)来编写Spark Streaming程序。所有这些都在本指南中介绍,您可以在本指南中找到标签, 让您可以选择不同语言的代码段。
Note(注意): 在 Python 有些API可能会有不同或不可用。在本指南, 您将找到Python API的标签来高亮显示不同的地方。
依赖
与Spark类似,Spark Streaming可以通过Maven来管理依赖。为了编写你自己的Spark Streaming 程序,你必须添加以下的依赖到你的SBT或者Maven项目中.
<pre><code><dependency>< groupId >org.apache.spark< /groupId >
< artifactId >spark-streaming_2.11< /artifactId >
< version >2.2.0< /version >
< /dependency ></code></pre>
初始化StreamingContext
为了初始化一个Spark Streaming程序, 一个StreamingContext对象必须要被创建出来,它是所有的 Spark Streaming功能的主入口点。
一个StreamingContext对象可以从一个SparkConf对象中来创建。
<pre><code>import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))
< /dependency ></code></pre>[]
这个appName参数是展示在集群UI界面上的应用程序的名称。master是一个Spark,Mesos or YARN cluster URL,或者一个特殊的"local[x ]"字符串以使用local mode(本地模式)来运行。在实践中,当在集群上运行时,你不会想在应用程序中硬编码 master,而是使用 spark-submit来启动应用程序 , 并且接受该参数. 然而,对于本地测试和单元测试,你可以传递 "local[x ]" 来运行Spark Streaming进程(检测本地系统中内核的个数)。请注意,做个内部创建了一个SparkContext(所有 Spark 功能的出发点),它可以像ssc.sparkContext这样被访问。
这个batch interval(批间隔)必须根据您的应用程序和可用的集群资源的等待时间要求进行设置。 更多详情请参阅优化指南部分。
一个StreamingContext对象也可以从一个现有的SparkContext对象来创建。
<pre><code>import org.apache.spark.streaming._
val sc = ... // 已存在的 SparkContext
val ssc = new StreamingContext(sc, Seconds(1))</code></pre>
- 在定义一个context之后,您必须执行以下操作。
通过创建输入DStreams来定义输入源。
通过应用转换和输出操作DStreams定义流计算(streaming computations)。
开始接收输入并且使用 streamingContext.start() 来处理数据。
使用streamingContext.awaitTermination() 等待处理被终止(手动或者由于任何错误)。
使用 streamingContext.stop() 来手动的停止处理。
- 需要记住的几点:
一旦一个context已经启动,将不会有新的数据流的计算可以被创建或者添加到它。
一旦一个context已经停止,它不会被重新启动。
同一时间内在JVM中只有一个StreamingContext可以被激活。
在 StreamingContext上的stop()同样也停止了SparkContext 。为了只停止StreamingContext ,设置stop()的可选参数,名叫 stopSparkContext为false。
一个SparkContext就可以被重用以创建多个StreamingContexts,只要前一个StreamingContext在下一个StreamingContext被创建之前停止(不停止 SparkContext)。
Discretized Streams (DStreams)(离散化流)
Discretized Stream or DStream 是Spark Streaming提供的基本抽象。它代表了一个连续的数据流, 无论是从 source(数据源)接收到的输入数据流, 还是通过转换输入流所产生的处理过的数据流. 在内部, 一个DStream被表示为一系列连续的RDDs, 它是Spark中一个不可改变的抽象, distributed dataset(的更多细节请看Spark编程指南。在一个DStream中的每个RDD包含来自一定的时间间隔的数据,如下图所示。

应用于DStream的任何操作转化为对于底层的RDDs的操作。 例如,在先前的示例,转换一个行(lines)流成为单词(words)中,flatMap操作被应用于在行离散流(lines DStream)中的每个 RDD来生成单词离散流(words DStream)的RDDs 。 如下所示:
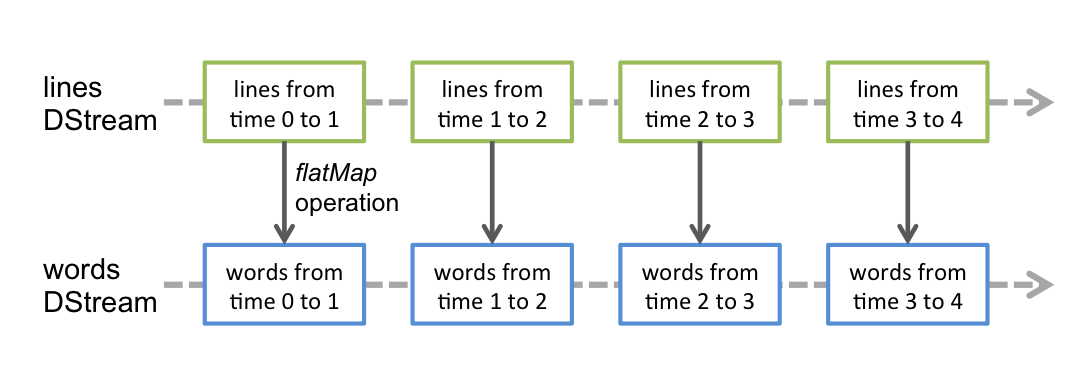
这些底层的RDD变换由Spark引擎(engine)计算。DStream操作隐藏了大多数这些细节并为了方便起见,提供给了开发者一个更高级别的API 。这些操作细节会在后边的章节中讨论。
Input DStreams 和 Receivers(接收器)
输入DStreams是代表输入数据是从流的源数据(streaming sources)接收到的流的 DStream。在 一个入门示例中, lines是一个input DStream, 因为它代表着从netcat服务器接收到的数据的流。每一个input DStream(除了 file stream 之外, 会在本章的后面来讨论)与一个 Receiver(Scala doc, Java doc)对象关联, 它从source(数据源)中获取数据,并且存储它到Sparl的内存中用于处理。
- Spark Streaming提供了两种内置的streaming source(流的数据源)。
Basic sources(基础的数据源): 在StreamingContext API中直接可以使用的数据源。例如: file systems和socket connections。
Basic sources(基础的数据源): 在StreamingContext API中直接可以使用的数据源。例如: file systems和socket connections。
请注意, 如果你想要在你的流处理程序中并行的接收多个数据流, 你可以创建多个input DStreams(在 性能优化 部分进一步讨论)。这将创建同时接收多个数据流的多个 receivers(接收器)。但需要注意,一个 Spark 的 worker/executor 是一个长期运行的任务(task),因此它将占用分配给 Spark Streaming的应用程序的所有核中的一个核(core)。因此,要记住,一个 Spark Streaming 应用需要分配足够的核(core)(或线程(threads),如果本地运行的话)来处理所接收的数据,以及来运行接收器(receiver(s))。
- 要记住的几点
当在本地运行一个Spark Streaming程序的时候,不要使用 “local” 或者 “local[1]” 作为 master的 URL。这两种方法中的任何一个都意味着只有一个线程将用于运行本地任务。如果你正在使用一个基于接收器(receiver)的输入离散流(input DStream)(例如,sockets,Kafka,Flume 等),则该单独的线程将用于运行接收器(receiver),而没有留下任何的线程用于处理接收到的数据。因此,在本地运行时,总是用 “local[n]” 作为 master URL,其中的 n > 运行接收器的数量(查看Spark属性来了解怎样去设置master的信息)。
将逻辑扩展到集群上去运行,分配给 Spark Streaming应用程序的内核(core)的内核数必须大于接收器(receiver)的数量。否则系统将接收数据,但是无法处理它。
Window Operations(窗口操作)
Spark Streaming也支持windowed computations(窗口计算),它允许你在数据的一个滑动窗口上应用 transformation(转换)。下图说明了这个滑动窗口。
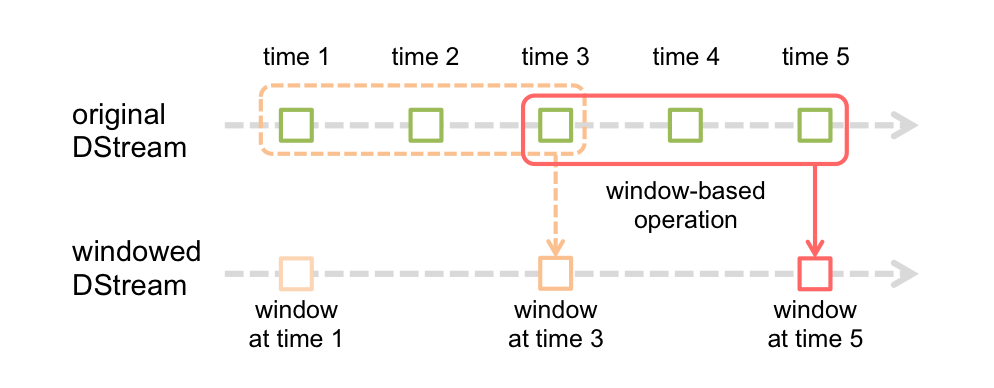
如上图显示,窗口在源DStream 上 slides(滑动),合并和操作落入窗内的源 RDDs,产生窗口化的 DStream的RDDs。在这个具体的例子中,程序在三个时间单元的数据上进行窗口操作,并且每两个时间单元滑动一次。这说明,任何一个窗口操作都需要指定两个参数。
window length(窗口长度) - 窗口的持续时间(图 3)。
sliding interval(滑动间隔) - 执行窗口操作的间隔(图 2)。
这两个参数必须是 source DStream的batch interval(批间隔)的倍数(图 1)。
让我们举例以说明窗口操作。例如,你想扩展前面的例子用来计算过去30秒的词频,间隔时间是10 秒。 为了达到这个目的,我们必须在过去30秒的(wrod, 1) pairs的pairs DStream上应用reduceByKey 操作。用方法reduceByKeyAndWindow实现。
<pre><code>// Reduce last 30 seconds of data, every 10 seconds
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))</code></pre>
Join操作
最后,它值得强调的是,您可以轻松地在Spark Streaming中执行不同类型的join。
- Stream-stream joins
Streams(流)可以非常容易地与其他流进行join。
<pre><code>val stream1: DStream[String, String] = ...
val stream2: DStream[String, String] = ...
val joinedStream = stream1.join(stream2)</code></pre>
这里,在每个 batch interval(批间隔)中,由stream1生成的RDD将与stream2生成的RDD进行 jion。你也可以做leftOuterJoin,rightOuterJoin,fullOuterJoin。此外,在 stream(流)的窗口上进行join通常是非常有用的。这也很容易做到。
<pre><code>val windowedStream1 = stream1.window(Seconds(20))
val windowedStream2 = stream2.window(Minutes(1))
val joinedStream = windowedStream1.join(windowedStream2)</code></pre>
- Stream-dataset joins
这在解释 DStream.transform操作时已经在前面演示过了。这是另一个 join window stream(窗口流)与 dataset 的例子。
<pre><code>val dataset: RDD[String, String] = ...
val windowedStream = stream.window(Seconds(20))...
val joinedStream = windowedStream.transform { rdd => rdd.join(dataset) }</code></pre>
实际上,您也可以动态更改要加入的dataset,提供给transform的函数是每个batch interval(批次间隔)进行评估,因此将使用dataset引用指向当前的dataset。
DStreams 上的输出操作
输出操作允许将DStream的数据推送到外部系统, 如数据库或文件系统。由于输出操作实际上允许外部系统使用变换后的数据, 所以它们触发所有DStream变换的实际执行(类似于RDD的动作)。目前, 定义了以下输出操作:
| Output Operation | Meaning |
|---|---|
| print() | 在运行流应用程序的driver节点上的DStream中打印每批数据的前十个元素。这对于开发和调试很有用。Python API这在 Python API中称为pprint()。 |
| saveAsTextFiles(prefix, [suffix]) | 将此 DStream 的内容另存为文本文件. 每个批处理间隔的文件名是根据 前缀 和 后缀 : "prefix-TIME_IN_MS[.suffix]" 生成的. |
| saveAsObjectFiles(prefix, [suffix]) | 将此 DStream 的内容另存为序列化 Java 对象的 SequenceFiles. 每个批处理间隔的文件名是根据 前缀 和 后缀 : "prefix-TIME_IN_MS[.suffix]" 生成的. Python API 这在Python API中是不可用的. |
| saveAsHadoopFiles(prefix, [suffix]) | 将此 DStream 的内容另存为Hadoop 文件. 每个批处理间隔的文件名是根据 前缀 和 后缀 : "prefix-TIME_IN_MS[.suffix]" 生成的. Python API 这在Python API中是不可用的. |
| foreachRDD(func) | 对从流中生成的每个 RDD 应用函数 func 的最通用的输出运算符. 此功能应将每个 RDD 中的数据推送到外部系统, 例如将 RDD 保存到文件, 或将其通过网络写入数据库. 请注意, 函数 func 在运行流应用程序的 driver 进程中执行, 通常会在其中具有 RDD 动作, 这将强制流式传输 RDD 的计算. |
Spark SQL
概述
Spark SQL是Spark处理结构化数据的一个模块。与基础的Spark RDD API不同,Spark SQL提供了查询结构化数据及计算结果等信息的接口。在内部,Spark SQL使用这个额外的信息去执行额外的优化。有几种方式可以跟Spark SQL进行交互,包括SQL和Dataset API。当使用相同执行引擎进行计算时, 无论使用哪种 API / 语言都可以快速的计算.这种统一意味着开发人员能够在基于提供最自然的方式来表达一个给定的transformation API之间实现轻松的来回切换不同的。
SQL
Spark SQL的功能之一是执行SQL查询,Spark SQL也能够被用于从已存在的Hive环境中读取数据。更多关于如何配置这个特性的信息, 请参考Hive表这部分。当以另外的编程语言运行SQL时, 查询结果将以 Dataset/DataFrame的形式返回。您也可以使用命令行或者通过JDBC/ODBC与SQL接口交互。
Datasets and DataFrames
一个Dataset是一个分布式的数据集合Dataset是在Spark 1.6中被添加的新接口,它提供了RDD的优点(强类型化, 能够使用强大的lambda函数)与Spark SQL执行引擎的优点。一个Dataset可以从JVM对象来构造并且使用转换功能(map,flatMap,filter,等等)。 Dataset API在Scala和Java是可用的.Python不支持Dataset API。但是由于Python的动态特性, 许多Dataset API的优点已经可用了 (也就是说, 你可能通过 name 天生的row.columnName属性访问一行中的字段),这种情况和R相似。
一个DataFrame是一个Dataset组成的指定列,它的概念与一个在关系型数据库或者在R/Python 中的表是相等的,但是有很多优化。DataFrames可以从大量的sources 中构造出来,比如:结构化的文本文件, Hive中的表,外部数据库,或者已经存在的RDDs。DataFrame API可以在Scala,Java,Python,和R中实现。在Scala和Java中,DataFrame由DataSet中的RowS(多个 Row)来表示。在the Scala API中, DataFrame仅仅是一个Dataset[Row]类型的别名。然而,在Java API中,用户需要去使用 Dataset
起始点: SparkSession
Spark SQL中所有功能的入口点是SparkSession 类。要创建一个 SparkSession, 仅使用 SparkSession.builder()就可以了:
<pre><code>import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
// For implicit conversions like converting RDDs to DataFrames
import spark.implicits._</code></pre>
Find full example code at "examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala" in the Spark repo. Spark 2.0 中的SparkSession为Hive特性提供了内嵌的支持,包括使用HiveQL编写查询的能力,访问 Hive UDF,以及从Hive表中读取数据的能力。为了使用这些特性, 你不需要去有一个已存在的Hive设置.
创建 DataFrames
在一个SparkSession中,应用程序可以从一个已经存在的RDD,从hive表,或者从Spark数据源中创建一个DataFrames。
举个例子, 下面就是基于一个JSON文件创建一个DataFrame:
val df = spark.read.json("examples/src/main/resources/people.json")
// Displays the content of the DataFrame to stdout
df.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+创建Datasets
Dataset与RDD相似,然而,并不是使用Java序列化或者Kryo编码器来序列化用于处理或者通过网络进行传输的对象。虽然编码器和标准的序列化都负责将一个对象序列化成字节,编码器是动态生成的代码,并且使用了一种允许Spark去执行许多像filtering,sorting以及hashing这样的操作,不需要将字节反序列化成对象的格式。
// Note: Case classes in Scala 2.10 can support only up to 22 fields. To work around this limit,
// you can use custom classes that implement the Product interface
case class Person(name: String, age: Long)
// Encoders are created for case classes
val caseClassDS = Seq(Person("Andy", 32)).toDS()
caseClassDS.show()
// +----+---+
// |name|age|
// +----+---+
// |Andy| 32|
// +----+---+
// Encoders for most common types are automatically provided by importing spark.implicits._
val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS.map(_ + 1).collect() // Returns: Array(2, 3, 4)
// DataFrames can be converted to a Dataset by providing a class. Mapping will be done by name
val path = "examples/src/main/resources/people.json"
val peopleDS = spark.read.json(path).as[Person]
peopleDS.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+ HBase开发指南
场景说明
假定用户开发一个应用程序,用于管理企业中的使用A业务的用户信息,如表1所示,A业务操作流程如下:
- 创建用户信息表。
- 在用户信息中新增用户的学历、职称等信息。
- 根据用户编号查询用户姓名和地址。
- 根据用户姓名进行查询。
- 查询年龄段在[20–29]之间的用户信息。
- 数据统计,统计用户信息表的人员数、年龄最大值、年龄最小值、平均年龄。
- 用户销户,删除用户信息表中该用户的数据。
- A业务结束后,删除用户信息表。
表1 用户信息
| 编号 | 姓名 | 性别 | 年龄 | 地址 |
|---|---|---|---|---|
| 12005000201 | 张三 | 男 | 19 | 广东省深圳市 |
| 12005000202 | 李婉婷 | 女 | 23 | 河北省石家庄市 |
| 12005000203 | 王明 | 男 | 21 | 浙江省宁波市 |
| 12005000204 | 李刚 | 男 | 25 | 湖北省襄阳市 |
| 12005000205 | 赵恩如 | 女 | 27 | 江西省上饶市 |
| 12005000206 | 陈龙 | 男 | 21 | 广东省深圳市 |
| 12005000207 | 周薇 | 女 | 19 | 湖南市株洲市 |
| 12005000208 | 杨艺文 | 女 | 23 | 河南省南阳市 |
| 12005000209 | 徐冰 | 男 | 18 | 重庆市开县 |
| 12005000210 | 肖凯 | 男 | 23 | 辽宁省大连市 |
创建表
HBase通过org.apache.hadoop.HBase.client.HBaseAdmin对象的createTable方法来创建表,并指定表名、列族名。创建表有两种方式:
- 快速建表,即创建表后整张表只有一个Region,随着数据量的增加会自动分裂成多个Region。
- 预分Region建表,即创建表时预先分配多个Region,此种方法建表可以提高写入大量数据初期的数据写入速度。
代码样例
下面代码片段在com.inspur.hadoop.HBase.example.TestSample类中:
创建Configuration
<pre><code>public Configuration getConfiguration(){
Configuration conf = HBaseConfiguration.create();
if (User.isHBaseSecurityEnabled(conf)){
//设置zookeeper server principal
System.setProperty("zookeeper.server.principal","zookeeper/hadoop");
//设置keberos认证方式,注[1]
System.setProperty("java.security.auth.login.config","/opt/client/HBase/HBase/ conf/jaas.conf");
conf.set("HBase.security.authentication", "kerberos");
System.setProperty("java.security.krb5.conf","/opt/inspur/Bigdata/etc/1_4_KerberosClient/krb5.conf");
}
return conf;
}
</code></pre>
创建用户信息表
public void testCreateTable()
{
// 指定表名
String tableName = "user";
// 创建Configuration实例,注[2]
Configuration conf = getConfiguration();
// 指定表描述信息对象
HTableDescriptor htd = new HTableDescriptor(TableName.valueOf(tableName));
// 指定列族名称为info,注[3]
HColumnDescriptor hcd = new HColumnDescriptor("info");
htd.addFamily(hcd);
HBaseAdmin admin = null;
try
{
// 实例化一个HBaseAdmin对象
admin = new HBaseAdmin(conf);
// 如果表存在,删除表
if(!admin.tableExists(tableName))
{
// 创建表,注[4]
admin.createTable(htd);
}
}
catch (IOException e)
{
e.printStackTrace();
}
finally
{
if(admin != null)
{
try
{
// 关闭HBaseAdmin对象
admin.close();
}
catch (IOException e)
{
e.printStackTrace();
}
}
}
}
删除表
HBase 通过HBaseAdmin的deleteTable方法来删除表。
代码样例
下面代码片段在com.inspur.hadoop.HBase.example.TestSample类中:
样例:删除表
public void dropTable()
{
// 指定表名
String tableName = "user";
// 创建Configuration实例
Configuration conf = getConfiguration();
HBaseAdmin admin = null;
try
{
admin = new HBaseAdmin(conf);
if (admin.tableExists(tableName))
{
// 删除表前,先disable表,注[1]
admin.disableTable(tableName);
// 删除表
admin.deleteTable(tableName);
}
}
catch (IOException e)
{
e.printStackTrace();
}
finally
{
if(admin != null)
{
try
{
// 关闭HBaseAdmin对象
admin.close();
}
catch (IOException e)
{
e.printStackTrace();
}
}
}
}
修改表
HBase通过HBaseAdmin的modifyTable和modifyColumn方法修改表信息。
代码样例
下面代码片段在com.inspur.hadoop.HBase.example.TestSample类中:
样例:修改表信息
public void testModifyTable()
{
// 指定表名
String tableName = "user";
// 指定列族名
byte[] familyName = Bytes.toBytes("education");
// 创建Configuration实例
Configuration conf = getConfiguration();
HBaseAdmin admin = null;
try
{
// 实例化一个HBaseAdmin对象
admin = new HBaseAdmin(conf);
// 获取表描述信息对象
HTableDescriptor htd = admin.getTableDescriptor(Bytes
.toBytes(tableName));
// 修改前,判断表是否有指定列族
if(!htd.hasFamily(familyName))
{
// 创建列描述对象
HColumnDescriptor hcd = new HColumnDescriptor(familyName);
htd.addFamily(hcd);
// 修改表前,你需要disable表,使表处于下线状态,注[1]
admin.disableTable(tableName);
// 提交modifyTable请求
admin.modifyTable(Bytes.toBytes(tableName), htd);
// 修改表后,你需要enable表,使表处于上线状态
admin.enableTable(tableName);
}
}
catch (IOException e)
{
e.printStackTrace();
}
finally
{
if(admin != null)
{
try
{
// 关闭HBaseAdmin对象
admin.close();
}
catch (IOException e)
{
e.printStackTrace();
}
}
}
}
插入数据
HBase是一个面向列的数据库,一行数据,可能对应多个列族,而一个列族又可以对应多个列。通常,写入数据的时候,我们需要指定要写入的列(含列族名称和列名称)。 HBase 通过HTable的put方法来插入数据。
代码样例
下面代码在com.inspur.hadoop.HBase.example.TestSample类中:
样例:插入数据
public void testPut()
{
// 指定表名
String tableName = "user";
// 指定列族名
byte[] familyName = Bytes.toBytes("info");
// 指定列名
byte[][] qualifiers = { Bytes.toBytes("name"), Bytes.toBytes("gender"),
Bytes.toBytes("age"), Bytes.toBytes("address") };
// 创建Configuration实例
Configuration conf = getConfiguration();
HTable table = null;
try
{
// 实例化一个HTable对象,注[1]
table = new HTable(conf, tableName);
List puts = new ArrayList();
// 实例化一个Put对象
Put put = new Put(Bytes.toBytes("012005000201"));
put.add(familyName, qualifiers[0], Bytes.toBytes("张三"));
put.add(familyName, qualifiers[1], Bytes.toBytes("男"));
put.add(familyName, qualifiers[2], Bytes.toBytes(new Long(19)));
put.add(familyName, qualifiers[3], Bytes.toBytes("广东省深圳市"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000202"));
put.add(familyName, qualifiers[0], Bytes.toBytes("李婉婷"));
put.add(familyName, qualifiers[1], Bytes.toBytes("女"));
put.add(familyName, qualifiers[2], Bytes.toBytes(new Long(23)));
put.add(familyName, qualifiers[3], Bytes.toBytes("河北省石家庄市"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000203"));
put.add(familyName, qualifiers[0], Bytes.toBytes("王明"));
put.add(familyName, qualifiers[1], Bytes.toBytes("男"));
put.add(familyName, qualifiers[2], Bytes.toBytes(new Long(26)));
put.add(familyName, qualifiers[3], Bytes.toBytes("浙江省宁波市"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000204"));
put.add(familyName, qualifiers[0], Bytes.toBytes("李刚"));
put.add(familyName, qualifiers[1], Bytes.toBytes("男"));
put.add(familyName, qualifiers[2], Bytes.toBytes(new Long(18)));
put.add(familyName, qualifiers[3], Bytes.toBytes("湖北省襄阳市"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000205"));
put.add(familyName, qualifiers[0], Bytes.toBytes("赵恩如"));
put.add(familyName, qualifiers[1], Bytes.toBytes("女"));
put.add(familyName, qualifiers[2], Bytes.toBytes(new Long(21)));
put.add(familyName, qualifiers[3], Bytes.toBytes("江西省上饶市"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000206"));
put.add(familyName, qualifiers[0], Bytes.toBytes("陈龙"));
put.add(familyName, qualifiers[1], Bytes.toBytes("男"));
put.add(familyName, qualifiers[2], Bytes.toBytes(new Long(32)));
put.add(familyName, qualifiers[3], Bytes.toBytes("湖南市株洲市"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000207"));
put.add(familyName, qualifiers[0], Bytes.toBytes("周微"));
put.add(familyName, qualifiers[1], Bytes.toBytes("女"));
put.add(familyName, qualifiers[2], Bytes.toBytes(new Long(29)));
put.add(familyName, qualifiers[3], Bytes.toBytes("河南省南阳市"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000208"));
put.add(familyName, qualifiers[0], Bytes.toBytes("杨艺文"));
put.add(familyName, qualifiers[1], Bytes.toBytes("女"));
put.add(familyName, qualifiers[2], Bytes.toBytes(new Long(30)));
put.add(familyName, qualifiers[3], Bytes.toBytes("重庆市开县"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000209"));
put.add(familyName, qualifiers[0], Bytes.toBytes("徐兵"));
put.add(familyName, qualifiers[1], Bytes.toBytes("男"));
put.add(familyName, qualifiers[2], Bytes.toBytes(new Long(26)));
put.add(familyName, qualifiers[3], Bytes.toBytes("陕西省渭南市"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000210"));
put.add(familyName, qualifiers[0], Bytes.toBytes("肖凯"));
put.add(familyName, qualifiers[1], Bytes.toBytes("男"));
put.add(familyName, qualifiers[2], Bytes.toBytes(new Long(25)));
put.add(familyName, qualifiers[3], Bytes.toBytes("辽宁省大连市"));
puts.add(put);
// 提交put数据请求
table.put(puts);
}
catch (IOException e)
{
e.printStackTrace();
}
finally
{
if(table != null)
{
try
{
// 关闭HTable对象
table.close();
}
catch (IOException e)
{
e.printStackTrace();
}
}
}
}
删除数据
HBase通过HTable的delete方法来删除数据,可以是一行数据也可以是数据集。
代码样例
下面代码在com.inspur.hadoop.HBase.example.TestSample类中:
样例:删除数据
public void testDelete()
{
// 指定表名
String tableName = "user";
// 指定rowKey值,即编号为012005000201
byte[] rowKey = Bytes.toBytes("012005000201");
// 创建Configuration实例
Configuration conf = getConfiguration();
HTable table = null;
try
{
// 实例化一个HTable对象
table = new HTable(conf, tableName);
// 实例化一个Delete对象
Delete delete = new Delete(rowKey);
// 提交一次delete数据请求
table.delete(delete);
}
catch (IOException e)
{
e.printStackTrace();
}
finally
{
if(table != null)
{
try
{
// 关闭HTable对象
table.close();
}
catch (IOException e)
{
e.printStackTrace();
}
}
}
}
使用Get读取数据
要从表中读取一条数据,首先需要实例化该表对应的HTable对象,然后创建一个Get对象。也可以为Get对象设定参数值,如列族的名称和列的名称。查询结果的该行数据存储Result对象中,Result中存储了多个Cell。
代码样例
下面代码在com.inspur.hadoop.HBase.example.TestSample类中:
样例:使用Get读取数据
public void testGet()
{
// 指定表名
String tableName = "user";
// 指定列族名
byte[] familyName = Bytes.toBytes("info");
// 指定列名
byte[][] qualifier = { Bytes.toBytes("name"), Bytes.toBytes("address") };
// 指定rowKey值
byte[] rowKey = Bytes.toBytes("012005000201");
// 创建Configuration实例
Configuration conf = getConfiguration();
HTable table = null;
try
{
// 实例化一个HTable对象
table = new HTable(conf, tableName);
// 实例化一个Get对象
Get get = new Get(rowKey);
// 设置列族和列名
get.addColumn(familyName, qualifier[0]);
get.addColumn(familyName, qualifier[1]);
// 提交一次get数据请求
Result result = table.get(get);
// 打印查询返回的数据
for (Cell cell : result.rawCells())
{
System.out.println(Bytes.toString(CellUtil.cloneRow(cell))
+ ":" + Bytes.toString(CellUtil.cloneFamily(cell))
+ "," + Bytes.toString(CellUtil.cloneQualifier(cell))
+ "," + Bytes.toString(CellUtil.cloneValue(cell)));
}
}
catch (IOException e)
{
e.printStackTrace();
}
finally
{
if (table != null)
{
try
{
// 关闭HTable对象
table.close();
}
catch (IOException e)
{
e.printStackTrace();
}
}
}
}
使用Scan读取数据
要从表中读取数据,首先需要实例化该表对应的HTable对象,然后创建一个Scan对象,并针对查询条件设置Scan对象的参数值,为了提高查询效率,最好指定StartRow和StopRow。查询结果的多行数据保存在ResultScanner对象,每行数据以Result对象形式存储,Result中存储了多个Cell。
代码样例
下面代码在com.inspur.hadoop.HBase.example.TestSample类中:
样例:使用Scan读取数据
public void testScanData()
{
// 指定表名
String tableName = "user";
// 创建Configuration实例
Configuration conf = getConfiguration();
HTable table = null;
try
{
// 实例化一个HTable对象
table = new HTable(conf, tableName);
// 实例化一个Scan对象,注[1]
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"));
//设置缓存大小,注[2]
scan.setCaching(5000);
scan.setBatch(2);
// 实例化一个ResultScanner对象
ResultScanner rScanner = null;
// 提交一次scan数据请求
rScanner = table.getScanner(scan);
// 打印查询返回的数据
for (Result r = rScanner.next(); r != null; r = rScanner.next())
{
for (Cell cell : r.rawCells())
{
System.out.println(Bytes.toString(CellUtil.cloneRow(cell))
+ ":" + Bytes.toString(CellUtil.cloneFamily(cell))
+ "," + Bytes.toString(CellUtil.cloneQualifier(cell))
+ "," + Bytes.toString(CellUtil.cloneValue(cell)));
}
}
}
catch (IOException e)
{
e.printStackTrace();
}
finally
{
if (table != null)
{
try
{
// 关闭HTable对象
table.close();
}
catch (IOException e)
{
e.printStackTrace();
}
}
}
}
MapReduce开发指南
样例场景说明
场景说明
假定用户有某个周末网民网购停留时间的日志文本,基于某些业务要求,要求开发MapReduce应用程序实现如下功能:
统计日志文件中本周末网购停留总时间超过2个小时的女性网民信息。、
周末两天的日志文件第一列为姓名,第二列为性别,第三列为本次停留时间,单位为分钟,分隔符为“,”。
log1.txt:周六网民停留日志
<pre><code>LiuYang,female,20
YuanJing,male,10
GuoYijun,male,5
CaiXuyu,female,50
Liyuan,male,20
FangBo,female,50
LiuYang,female,20
YuanJing,male,10
GuoYijun,male,50
CaiXuyu,female,50
</code></pre>
log2.txt:周日网民停留日志
LiuYang,female,20
YuanJing,male,10
CaiXuyu,female,50
FangBo,female,50
GuoYijun,male,5
CaiXuyu,female,50
Liyuan,male,20
CaiXuyu,female,50
FangBo,female,50
LiuYang,female,20
YuanJing,male,10
FangBo,female,50
GuoYijun,male,50
CaiXuyu,female,50
数据规划
首先需要把原日志文件放置在HDFS系统里:
1.本地新建两个文本文件,将log1.txt中的内容复制保存到input_data1.txt,将log2.txt中的内容复制保存到input_data2.txt。
2.在HDFS上建立一个文件夹,“/tmp/input”,并上传input_data1.txt,input_data2.txt到此目录,命令如下:
在Linux系统HDFS客户端使用命令HDFS dfs -mkdir /tmp/input
在Linux系统HDFS客户端使用命令HDFS dfs -put local_filepath /tmp/input
开发思路
统计日志文件中本周末网购停留总时间超过2个小时的女性网民信息。 主要分为四个部分:
1.读取原文件数据。
2.筛选女性网民上网时间数据信息。
3.汇总每个女性上网总时间。
4.筛选出停留时间大于两个小时的女性网民信息。
样例代码说明
统计日志文件中本周末网购停留总时间超过2个小时的女性网民信息。
主要分为三个部分:
1.从原文件中筛选女性网民上网时间数据信息,通过类CollectionMapper继承Mapper抽象类实现。
2.汇总每个女性上网时间,并输出时间大于两个小时的女性网民信息,通过类CollectionReducer继承Reducer抽象类实现。
3.main方法提供建立一个MapReduce job,并提交MapReduce作业到hadoop集群。
代码样例
样例1:类CollectionMapper定义Mapper抽象类的map()方法和setup()方法。
public static class CollectionMapper extends Mapper {
// 分隔符。
String delim;
// 性别筛选。
String sexFilter;
// 姓名信息。
private Text nameInfo = new Text();
// 输出的key,value要求是序列化的。
private IntWritable timeInfo = new IntWritable(1);
/**
* 分布式计算
*
* @param key
* Object : 原文件位置偏移量。
* @param value
* Text : 原文件的一行字符数据。
* @param context
* Context : 出参。
* @throws IOException
* , InterruptedException
*/
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
if (line.contains(sexFilter)) {
// 读取的一行字符串数据。
String name = line.substring(0, line.indexOf(delim));
nameInfo.set(name);
// 获取上网停留时间。
String time = line.substring(line.lastIndexOf(delim) + 1, line.length());
timeInfo.set(Integer.parseInt(time));
// map输出key,value键值对。
context.write(nameInfo, timeInfo);
}
}
/**
* map调用,做一些初始工作。
*
* @param context
* Context
*/
public void setup(Context context) throws IOException, InterruptedException {
// 通过Context可以获得配置信息。
delim = context.getConfiguration().get("log.delimiter", ",");
sexFilter = delim + context.getConfiguration().get("log.sex.filter", "female") + delim;
}
}
样例2:类CollectionReducer定义Reducer抽象类的reduce()方法。
public static class CollectionReducer extends Reducer {
// 统计结果。
private IntWritable result = new IntWritable();
// 总时间门槛。
private int timeThreshold;
/**
* @param key
* Text : Mapper后的key项。
* @param values
* Iterable : 相同key项的所有统计结果。
* @param context
* Context
* @throws IOException
* , InterruptedException
*/
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
// 如果时间小于门槛时间,不输出结果。
if (sum < timeThreshold) {
return;
}
result.set(sum);
// reduce输出为key:网民的信息,value:该网民上网总时间。
context.write(key, result);
}
/**
* setup()方法只在进入map任务的map()方法之前或者reduce任务的reduce()方法之前调用一次。
*
* @param context
* Context
* @throws IOException
* , InterruptedException
*/
public void setup(Context context) throws IOException, InterruptedException {
// Context可以获得配置信息。
timeThreshold = context.getConfiguration().getInt("log.time.threshold", 120);
}
}
样例3:main()方法创建一个job,指定参数,提交作业到hadoop集群。
public static void main(String[]args)throws Exception{
// 初始化环境变量。
Configuration conf=new Configuration();
// 安全登录。
LoginUtil.login(PRINCIPAL,KEYTAB,KRB,conf);
// 获取入参。
String[]otherArgs=new GenericOptionsParser(conf,args).getRemainingArgs();if(otherArgs.length!=2){System.err.println("Usage: collect female info ");System.exit(2);}
// 初始化Job任务对象。
@SuppressWarnings("deprecation") Job job=new Job(conf,"Collect Female Info");job.setJarByClass(FemaleInfoCollector.class);
// 设置运行时执行map,reduce的类,也可以通过配置文件指定。
job.setMapperClass(CollectionMapper.class);job.setReducerClass(CollectionReducer.class);
// 设置combiner类,默认不使用,使用时通常使用和reduce一样的类。
// Combiner类需要谨慎使用,也可以通过配置文件指定。
job.setCombinerClass(CollectionReducer.class);
// 设置作业的输出类型。
job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job,new Path(otherArgs[0]));FileOutputFormat.setOutputPath(job,new Path(otherArgs[1]));
// 提交任务交到远程环境上执行。
System.exit(job.waitForCompletion(true)?0:1);}样例4:类CollectionCombiner实现了在map端先合并一下map输出的数据,减少map和reduce之间传输的数据量。
/**
* Combiner class
*/
public static class CollectionCombiner extends Reducer {
// Intermediate statistical results
private IntWritable intermediateResult = new IntWritable();
/**
* @param key
* Text : key after Mapper
* @param values
* Iterable : all results with the same key in this map task
* @param context
* Context
* @throws IOException
* , InterruptedException
*/
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
intermediateResult.set(sum);
// In the output information, key indicates netizen information,
// and value indicates the total online time of the netizen in this
// map task.
context.write(key, intermediateResult);
}
}
Sqoop开发指南
导入工具介绍
Sqoop为一系列相关工具的集合。您可以指定想要使用的工具和控制该工具的参数。使用方法:
<pre><code>$ sqoop tool-name [tool-arguments]
</code></pre>
Sqoop配有一个帮助工具。 要显示所有可用工具的列表,请键入以下命令:
<pre><code>$ sqoop help
usage: sqoop COMMAND [ARGS]
Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import mainframe datasets to HDFS
list-databases List available databases on a server
list-tables List available tables in a database
version Display version information
See 'sqoop help COMMAND' for information on a specific command.
</code></pre>
您可以通过输入以下方式显示特定工具的帮助:“sqoop help(tool-name)”;例如:sqoop help import。您还可以添加--help参数到任何命令:“sqoop import –help”。
使用命令别名
除了键入Sqoop(toolname)语法之外,还可以使用指定sqoop-(toolname)语法的别名脚本。 例如,脚本sqoop-import,sqoop-export等都选择一个特定的工具。
使用选项文件传递参数
当使用Sqoop时,为了方便起见,可以将经常使用的命令行参数放到选项文件中。选项文件是一个文本文件,其中每行按照命令行上显示的顺序标识一个选项。选项文件允许在行中间使用反斜杠,从而允许用多行指定一个选项。选项允许有注释。注释必须另起一行指定,而不能与选项文本混合使用。当扩展选项文件时,所有注释和空行将被忽略。除非选项显示为带引号的字符串,否则任何前导或尾部空格都将被忽略。 选项文件可以在命令行的任何位置指定,只要其中的选项遵循另外规定的选项排序规则即可。例如,不管从哪里加载选项,他们都必须按照顺序进行操作,以便通用选项首先出现,工具特定选项其后出现,最后是传递给子程序的选项。 要指定选项文件,只需在方便的位置创建一个选项文件,并通过--options-file参数将其传递给命令行。 每当指定一个选项文件时,它将在调用该工具之前在命令行中进行扩展。如果需要,您可以在同一个调用中指定多个选项文件。 如下两种使用方法可以相互替换:
<pre><code>$ sqoop import --connect jdbc:mysql://localhost/db --username foo --table TEST
$ sqoop --options-file /users/homer/work/import.txt --table TEST
</code></pre>
    其中/users/homer/work/import.txt包含如下内容:
<pre><code>import
--connect
jdbc:mysql://localhost/db
--username
foo
</code></pre>
选项文件可以有空行和注释,提高可读性。因此,如果选项文件包含如下内容,上述示例将正常工作:
<pre><code>import
--connect jdbc:mysql://localhost/db
--username
</code></pre>
工具详细介绍
import
import工具将单个表从关系型数据库导入到HDFS。表中的每一行都表示为HDFS中的单独记录。记录可以存储为文本文件(每行一条记录),也可以以二进制形式存储为Avro或者SequenceFiles。
语法
工具使用泛型:
<pre><code>$ sqoop import (generic-args) (export-args)
$ sqoop import (generic-args) (export-args)
</code></pre>
连接数据库
Sqoop旨在将数据库中的表导入到HDFS。为此,您必须指定一个连接字符串,描述如何连接到数据库。连接字符串与URL类似,并通过--connect参数传递给Sqoop,它描述了要连接的服务器和数据库,也可以指定端口。例如:
<pre><code>$ sqoop import --connect jdbc:mysql://database.example.com/employees
</code></pre>
该字符串将连接到主机database.example.com上名为employees的MySQL数据库。
选择导入数据
Sqoop通常以表为中心的方式导入数据。使用--table参数选择要导入的数据库表。例如,--table employee,该参数还可以在数据库中标识VIEW或其他类似于表的实体。
默认情况下,选择表中的所有列进行导入。导入的数据以“自然顺序”写入HDFS。也就是说,包含列A,B和C的表导入后的数据如下:
<pre><code>A1,B1,C1
A2,B2,C2
...
</code></pre>
您可以通过使用--columns参数来选择列的一个子集并控制它们的排序。它包括以逗号分隔的要导入的列,例如: --columns “name,employee_id,jobtitle”。
您可以通过向导入语句添加SQL WHERE子句来控制哪些行被导入。 默认情况下,Sqoop生成“SELECT ”形式的语句。 您可以使用--where参数附加一个WHERE子句。例如: --where “id> 400”。只有id的值大于400的行将被导入。
自由格式数据导入
Sqoop也可以导入任意SQL查询的结果集,而不是使用--table,--columns和--where参数,您可以使用--query参数指定一个SQL语句。
导入自由格式查询时,必须使用--target-dir指定目标目录。
如果要并行导入查询结果,则每个map任务都需要执行查询的副本,按照Sqoop推断的边界条件进行分区。您的查询必须包含每个采集进程将用唯一条件表达式替换的标识$CONDITIONS。除此之外,您还必须使用--split-by选择一个分割列。例如:
<pre><code>$ sqoop import --query 'SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS' --split-by a.id --target-dir /user/foo/joinresults
</code></pre>
或者,查询可以执行一次并连续导入,通过使用-m 1指定单个map任务:
<pre><code>$ sqoop import --query 'SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS' -m 1 --target-dir /user/foo/joinresults
</code></pre>
导入数据到Hive
Sqoop的import工具主要功能是将数据上传到HDFS中的文件中。 如果您的Hive与您的HDFS集群相关联,则Sqoop还可以通过生成和执行CREATE TABLE语句将数据导入Hive。将数据导入Hive就像将--hive-import选项添加到采集系统命令行一样简单。
如果Hive表已经存在,您可以指定--hive-overwrite选项来指示必须替换Hive中的现有表。将数据导入到HDFS或省略此步骤后,Sqoop将生成一个Hive脚本,其中包含使用Hive的类型来定义列的CREATE TABLE操作,以及一个LOAD DATA INPATH语句将数据文件移动到Hive的仓库目录中。
在Sqoop所在的机器上,通过调用该机器上的Hive副本来执行脚本。如果您有装有多个Hive,或者hive不在$PATH中,请使用--hive-home选项来标识Hive安装目录。 Sqoop将从这里使用$HIVE_HOME / bin / hive。
即使Hive支持转义字符,但它不能处理转义的新行字符。 而且,它不支持在字符串中包含字段分隔符的字符串。因此,建议您选择明确的字段和记录终止分隔符,而无需在使用Hive时转义字符; 这是由于Hive的输入解析能力有限。如果在将数据导入Hive时使用--escape-by,-enclosed-by或--olectually-surround-by,Sqoop将打印一条警告消息。
如果数据库的行中包含Hive的默认行分隔符(\n和\r字符)或列分隔符(\01字符)的字符串字段,则Sqoop导入的数据会存在问题。您可以使用--hive-drop-import-delims选项去掉这些字符,以提供与Hive兼容的文本数据。或者,您可以使用--hive-delims-replacement选项在导入时将这些字符替换为用户定义字符串,以提供与Hive兼容的文本数据。只有在使用Hive的默认分隔符时才应使用这些选项,如果指定了不同的分隔符,则不应使用这些选项。
Sqoop将字段和行分隔符传递给Hive。如果没有设置任何分隔符,并且使用--hive-import,则字段分隔符将被设置为^A,并且行分隔符将被设置为\n,与Hive的默认值一致。
导入数据到HBase
信息采集系统支持超出HDFS和Hive的额外导入目标。Sqoop也可以将记录导入到HBase表中。
通过指定--hbase-table,您可以指示Sqoop导入HBase中的表,而不是HDFS中的目录。Sqoop将导入数据到指定为-hbase-table的参数的表。输入表的每一行将被转换为输出表的HBase Put操作,转为输出表的一行。每行的键是输入的一列。默认情况下,Sqoop将使用split-by指定的列作为行键。如果没有指定,它将尝试标识源表的主键列(如果有)。您可以使用--hbase-row-key手动指定行键。每个输出列将被放置在使用--column-family指定的列族中。
如果输入表具有复合键,则--hbase-row-key必须是以逗号分隔的复合键属性列表的形式。在这种情况下,HBase行的行键将通过使用组合复合键属性的值来生成。注意:对于具有复合键的表,必须指定--hbase-row-key。
如果目标表和列族不存在,则Sqoop的任务将退出并显示错误。您应该在运行导入之前创建目标表和列族。如果指定了-hbase-create-table,则Sqoop将使用HBase配置中的默认参数创建目标表和列族(如果不存在)。
Sqoop通过将每个字段转换为其对应的字符串表示,然后将其序列化到HBase(如同在文本模式下导入到HDFS),然后将该字符串的UTF-8编码的字节插入到目标单元格中。Sqoop将跳过除行键外的所有列值均为空的行。
为了减少HBase的负载,Sqoop可以进行批量加载,而不是直接写入。如果使用批量加载,请使用--hbase-bulkload选项启用它。
导入到Kafka
我们对原生Sqoop做了修改,增加了关系型数据库向Kafka导入数据的功能。 导入Kafka的使用方法同导入HDFS类似,唯一区别就是将导入HDFS时用到的--target-dir参数换成导入Kafka需要的--topic和—broker-list两个参数。
使用示例:
<pre><code>$ sqoop import --connect jdbc:mysql://hd151.bd:3306/hdfs_test --username root --password 123456 --table income --topic income_detail --broker-list hd151.bd:6667
</code></pre>
Oozie开发指南
样例场景说明
场景说明
假设存在这样的业务需求: 每天需要对网站的日志文件进行离线分析,统计出网站各模块的访问频率(日志文件存放在HDFS中)。
操作步骤
- 业务分析
1.可以使用客户端样例目录中MapReduce程序对日志目录的数据进行分析、处理。
2.将MapReduce程序的分析结果移动到数据分析结果目录,并将数据文件的权限设置成660。
3.为了满足每天分析一次的需求,需要每天重复执行一次步骤1.1~ 步骤1.2。
- 业务实现
1.使用PUTTY工具登录Oozie客户端所在节点,新建dataLoad目录,作为程序运行目录,后面编写的文件均保存在该目录下。例如“/opt/InspurInsight_Client/Oozie/oozie-client-4.0.1/examples/apps/dataLoad/”。(说明:可以直接复制样例目录中map-reduce文件夹内的内容到dataLoad文件夹,然后进行编辑)
2.编写流程任务属性文件(job.properties)。
3.编写Workflow任务-workflow.xml。
流程文件样例
<pre><code><?xml version="1.0" encoding="utf-8"?>
<workflow-app xmlns="uri:oozie:workflow:0.2" name="data_load">
<start to="mr-dataLoad"/>
<action name="mr-dataLoad">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/${wf:user()}/${dataLoadRoot}/output-data/map-reduce"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<property>
<name>mapred.mapper.class</name>
<value>org.apache.oozie.example.SampleMapper</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.apache.oozie.example.SampleReducer</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>/user/oozie/${dataLoadRoot}/input-data/text</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>/user/${wf:user()}/${dataLoadRoot}/output-data/map-reduce</value>
</property>
</configuration>
</map-reduce>
<ok to="copyData"/>
<error to="fail"/>
</action>
<action name="copyData">
<fs>
<delete path="${nameNode}/user/oozie/${dataLoadRoot}/result"/>
<move source="${nameNode}/user/${wf:user()}/${dataLoadRoot}/output-data/map-reduce" target="${nameNode}/user/oozie/${dataLoadRoot}/result"/>
<chmod path="${nameNode}/user/oozie/${dataLoadRoot}/result" permissions="-rwxrw-rw-" dir-files="true"/>
</fs>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>This workflow failed, error message[$ {wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
</code></pre>`
4.编写Coordinator任务-coordinator.xml。
完成每天一次的定时数据分析工作,请参见coordinator.xml。
- 上传流程文件
1.使用或切换到拥有HDFS上传权限的用户。
2.使用该用户进行Kerberos认证,认证过程可参见开发环境准备。
3.使用HDFS上传命令,将dataLoad目录上传到HDFS某个指定目录(oozie_cli用户需要对该目录有读写权限)。
说明:该指定目录需要与之前job.properties中定义的oozie.coord.application.path属性和workflowAppUri属性的值保持一致。
- 执行流程文件
1.使用oozie_cli用户进行Kerberos认证。
2.启动流程。
命令:
oozie client 安装目录 /bin/oozie job -oozie https://oozie server ip:port/oozie –config job.properties 文件所在路径 –run
例如: /opt/oozie-client-4.0.1/bin/ooziejob -oozie https://10.1.130.10:21003/oozie -configjob.properties –run
样例代码说明
- job.properties
功能描述:流程的属性定义文件,定义了流程运行期间使用的外部参数值对。
样例代码
<pre><code>nameNode=HDFS://10.1.130.11:25000
jobTracker=10.1.130.10:26004
queueName=QueueA
dataLoadRoot=examples
oozie.coord.application.path=${nameNode}/user/oozie_cli/${dataLoadRoot}/apps/dataLoad
start=2013-04-02T00:00Z
end=2014-04-02T00:00Z
workflowAppUri=${nameNode}/user/oozie_cli/${dataLoadRoot}/apps/dataLoad
</code></pre>
- workflow.xml
功能描述:描述了一个完整业务的流程定义文件。一般由一个start节点、一个end节点和多个实现具体业务的action节点组成。
样例代码
<pre><code><workflow-app xmlns="uri:oozie:workflow:0.2" name="data_load">
<start to="copyData"/>
<action name="copyData">
</action>
……
<end name="end"/>
</workflow-app>
</code></pre>
- Start Action
功能描述:流程任务的执行入口,每个流程任务有且仅有一个该节点。
样例代码
<pre><code><start to="mr-dataLoad"/>
</code></pre>
- End Action
功能描述:流程任务执行的终点,每个流程任务有且仅有一个该节点。
样例代码
<pre><code><end name="end"/>
</code></pre>
- Kill Action
功能描述:流程任务运行期间发生异常后,流程的异常结束节点。
样例代码
<pre><code><kill name="fail">
<message>
This workflow failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
</message>
</kill>
</code></pre>
- FS Action
功能描述:HDFS文件操作节点,支持对HDFS文件及目录的创建、删除、授权功能。
样例代码
<pre><code><action name="copyData">
<fs>
<delete path='${nameNode}/user/oozie_cli/${dataLoadRoot}/result'/>
<move source='${nameNode}/user/${wf:user()}/${dataLoadRoot}/output-data/map-reduce'
target='${nameNode}/user/oozie_cli/${dataLoadRoot}/result'/>
<chmod path='${nameNode}/user/oozie_cli/${dataLoadRoot}/reuslt' permissions='-rwxrw-rw-'
dir-files='true'></chmod>
</fs>
<ok to="end"/>
<error to="fail"/>
</action>
</code></pre>
- MapReduce Action
功能描述:MapReduce任务节点,负责执行一个map-reduce任务。 样例代码
<pre><code><action name="mr-dataLoad">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/${wf:user()}/${dataLoadRoot}/output-data/map-reduce"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<property>
<name>mapred.mapper.class</name>
<value>org.apache.oozie.example.SampleMapper</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.apache.oozie.example.SampleReducer</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>/user/oozie/${dataLoadRoot}/input-data/text</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>/user/${wf:user()}/${dataLoadRoot}/output-data/map-reduce</value>
</property>
</configuration>
</map-reduce>
<ok to="copyData"/>
<error to="fail"/>
</action>
</code></pre>
- coordinator.xml
功能描述:周期性执行workflow类型任务的流程定义文件。
样例代码
<pre><code> <coordinator-app name="cron-coord" frequency="${coord:days(1)}" start="${start}" end="${end}"
timezone="UTC" xmlns="uri:oozie:coordinator:0.2">
<action>
<workflow>
<app-path>${workflowAppUri}</app-path>
<configuration>
<property>
<name>jobTracker</name>
<value>${jobTracker}</value>
</property>
<property>
<name>nameNode</name>
<value>${nameNode}</value>
</property>
<property>
<name>queueName</name>
<value>${queueName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
</code></pre>