产品简介
浪潮云托管Hadoop服务遵循Hadoop技术路线,为海量(TB/PB级)数据提供分布式处理服务,方便开发者轻松跨越大数据分布式计算环境搭建、运维等繁琐工作, 直接专注于数据分析、数据挖掘、商业智能等应用场景。HDInsight包含Hive、Spark、Storm、Kafka、Sqoop、Zeppelin、Oozie、Solr等大数据处理的主流技术组件, 提供了从自动化部署运维、资源隔离、资源调度、数据计算任务执行及跟踪等全套解决方案。
产品优势
- 安全可靠
提供授权、认证、审计、加密的数据安全机制。
- 弹性伸缩
根据业务成长,灵活弹性扩展大数据服务计算资源。
- 高可用
支撑超大规模集群的稳定运行,支持资源合理按需分配,任务智能化调度,服务实时监控和自愈。
- 灵活高效
集成MapReduce与Spark双数据处理引擎,极大提高数据运算处理效率。
- 兼容开放
兼容Hadoop开源生态,支持应用无缝迁移。
产品功能
- 按需创建集群
提供可视化集群创建能力,可自由选择服务器规模,支持根据业务量增长而对集群动态扩容。
- 数据集成
提供数据抽取转化加载能力,可采集非结构化、半结构化和结构化数据,并集成到HDInsight服务提供的存储介质中或第三方中间件。
- 数据存储
与分布式文件系统、非关系型数据库及传统数据库无缝集成,支持不同存储场景。
- 数据计算
支持MapReduce、Spark、Storm等多种开源计算框架,可实现批量计算和实时计算,并支持对计算结果极速查询。
- 多类型作业管理
支持多种作业类型,包括离线处理作业、关系型分析查询作业、机器学习作业、图处理作业等。
- 资源调度
可以对服务实例中各个作业任务,根据其优先级、资源使用限制自动进行调度,同时还可以设置多种资源调度算法,满足不同场景的多任务资源调度。
- 数据安全管理
提供用户认证、用户权限(数据访问权限、服务组件使用权限)和数据加密等一系列安全机制。集群在响应用户请求时,对用户身份进行认证;同时校验用户是否有权限访问数据以及是否有权限使用该服务组件。另外,HDInsight服务还提供数据加密能力,确保数据安全。
产品架构
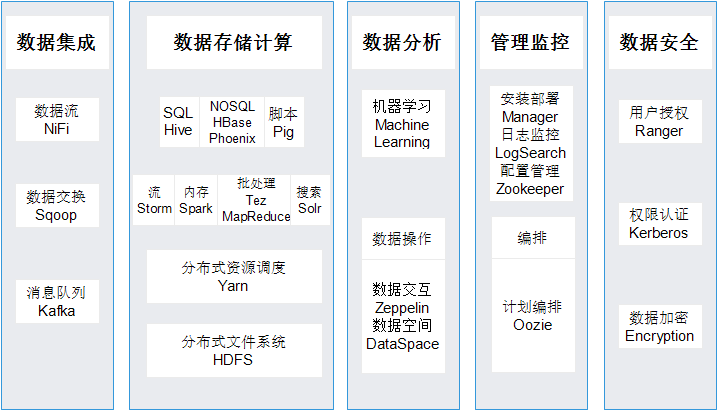
应用场景
批处理ETL
传统的OLTP系统、数据仓库、客户关系库或者一些线上的应用服务器采用批处理进行数据处理,但是批处理处理时间较长,输入输出的数据量大,数据的装载、转换以及清洗易出错。借助大数据 HDInsight可以通过Flume或者Sqoop导入到HDFS上,作为原始数据存放。如果合适,可以将这部分原始数据转载成列式存储的文件格式。之后可以借助一些图形化的配置工具或者脚本来定义ETL的处理流程,调用Hive来完成数据处理。执行引擎可以选择MapReduce或者是Spark。用列式存储处理生成的中间结果。
在线服务应用
与传统的在线应用相比,基于HBase的方案优势在于良好的水平可扩展性、高可靠性及高并发性。在线应用的数据源主要有两种:一种是存量数据,来源于DW或者一些备份库上;还有一种来自于线上系统实时产生的数据。对于存量数据可以先导入到HDFS上,然后通过批处理引擎加载进HBase库。数据先加载进HDFS,有几个原因:1)可以减少对其他系统的依赖;2)提高加载的性能(如果从其他系统直接加载入HBase,系统之间的数据访问性能得不到保障);3)载入的HDFS数据可以用于OLAP的应用。对于实时数据可以通过Flume或者Kafka采集进来,借助于Spark Streaming对实时数据做一些过滤或者统计(这个处理过程可选),然后载入HBase,通过HBase的API或者SQL前端(如Apache Phoenix)进行在线数据查询。
实时数据分析
实时数据分析的时间窗口一般都在秒级,如实时的文本搜索、实时推荐引擎等。这种分析的数据源一般都来自线上系统,或是外部捕获的实时数据。获取的数据可以通过Flume和Kafka加载入Hadoop平台,数据一方面可以存入HDFS,其中保存了全量数据,可以对数据做全量的或者批量的分析;另一方面数据可以经过Spark Streaming引擎,它只是对一个很小的时间窗口数据进行分析。在HDFS上的数据可用于建模,模型可以存入分布式数据库,并做定期的模型修正。实时处理模块可以从分布式数据库中获取相应的模型,并对实时数据使用模型计算出实时的结果,这些结果可以用于线上系统的实时展现。
产品术语
| 术语 | 解 释 |
|---|---|
| Hadoop | Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 |
| HDFS | HDFS作为分布式文件系统(Hadoop Distributed File System),提供高吞吐量的数据访问,为海量数据提供存储。HDFS是一个高度容错性的系统, 基于高可用架构(HA)保证集群的可用性。 |
| MapReduce | 并行计算软件框架,依靠容错方式并行处理TB级别数据。 |
| Yarn | Yarn是Hadoop 资源管理器,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享带来好处。 |
| HBase | 一款高可靠、高性能,使用列式存储的分布式存储系统。 |
| Hive | 建立在Hadoop之上的数据仓库,提供HiveQL类SQL语言操作结构化数据。 |
| Storm | 分布式、可靠、容错的数据流处理系统, |
| Spark | 分布式批处理框架,提供分析挖掘和迭代式内存计算能力,支持多种语言。 |
| Zookeeper | 可为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册等功能。其目标是封装复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。 |
| Kafka | 一种高吞吐量的分布式发布订阅消息系统 |
| Tez | 一个针对Hadoop数据处理应用程序的分布式执行框架 |
| Sqoop | 一个用来将Hadoop和关系型数据库中的数据相互转移的工具 |
| Pig | MapReduce的一个抽象,是一个工具/平台,用于分析较大的数据集,并将它们表示为数据流。Pig通常与 Hadoop 一起使用 |
| Solr | 一个开源搜索平台,用于构建搜索应用程序 |